
News Update
4月 18 日,Meta 发布两款开源 Llama 3 8B 与 Llama 3 70B 模型,供外部开发者免费使用。此次发布不仅是技术革新的展示,也是开放源代码精神的体现,预示着 AI 应用的新篇章即将开启。此次,Meta 共开源了 Llama 3 8B 和 Llama 3 70B 两款模型,分别有预训练和指令微调两个版本。
小红书自主研发了一款跨平台播放器 —— REDPlayer。不同于行业其他播放器,REDPlayer 具有结构简单、耦合度低、功能边界清晰等特点,提供了多种接入方式,技术人员可根据需要灵活选择,既可快速集成 SDK 使用,也可基于源码进行定制开发。
近日,由蚂蚁集团和浙江大合研发的大模型知识抽取框架OneKE宣布开源,并且捐赠给OpenKG开放知识图谱社区。
蚂蚁集团和浙江大合构建和升级了蚂蚁百灵大模型在知识抽取领域的能力,并发布中英双语大模型知识抽取框架OneKE,同时开源基于LLaMA2全参数微调的版本。测评指标显示,OneKE在多个全监督及零样本实体/关系/事件抽取任务上取得了相对较好的效果。
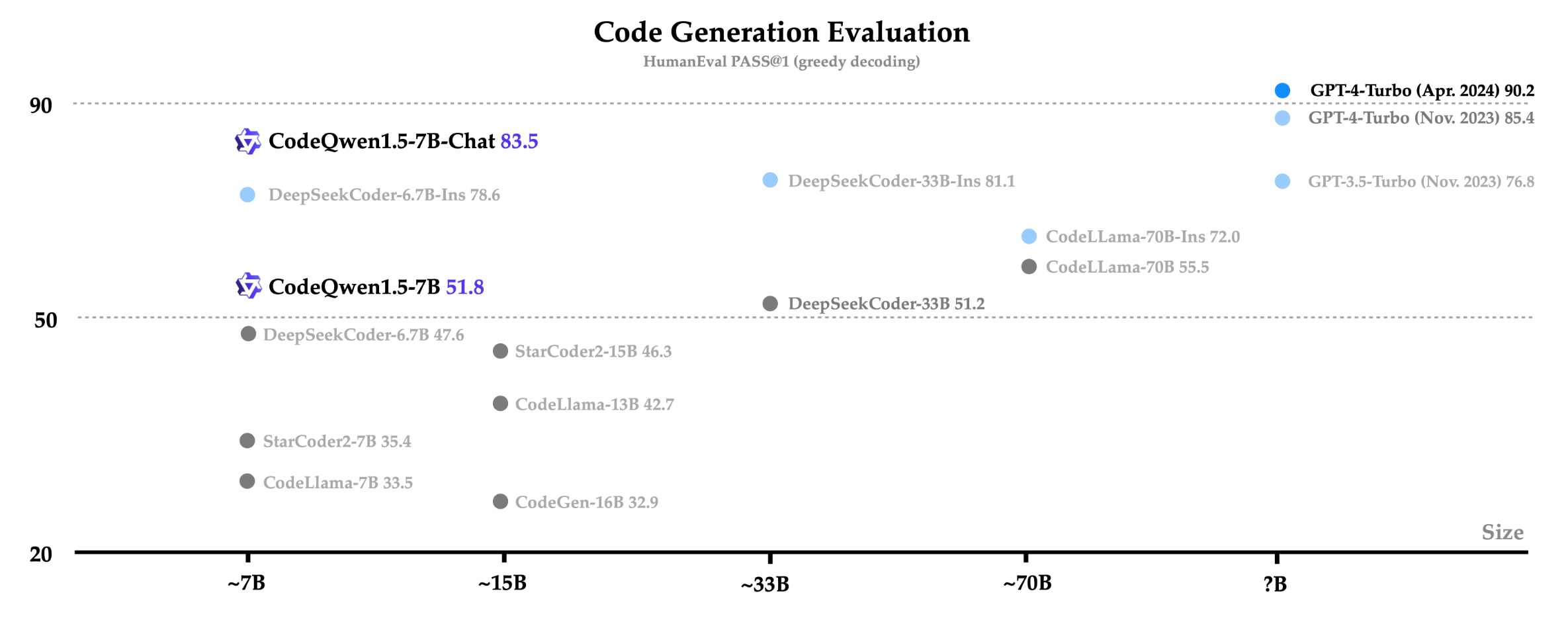
阿里最新发布了 CodeQwen1.5-7B 和 CodeQwen1.5-7B-Chat。它们是基于 Qwen1.5 语言模型开发的专用代码 LLMs 。新模型使用了 3T 令牌的代码数据进行训练,在代码生成、长上下文建模(64K)、代码编辑和 SQL 等方面表现出色。
太不给面子了,在李彦宏公开表示「开源模型只会越来越落后」3天之后,AI行业的活菩萨Meta今天发布了开源大模型Llama 3,70B版本的综合能力已经和Claude 3中配版不相上下,正在训练还有一个400B版本内测时超过了Claude 3顶配版……
-Meta是目前大模型开源届的中流砥柱,目前判断LLAMA-3系列都会开源,包括400B的模型也会在几个月后开源出来,这意味着我们会拥有效果与GPT 4基本持平的开源大语言模型,这对于很多复杂应用来说是个很好的消息(当然400B规模的模型太大,这是个实际问题)。
-如果Meta 的LLAMA-3系列全面开源,甚至之后的LLAMA-4也持续开源(目前看这个可能性是较大的,Meta的开源决心比较大,相比而言,谷歌还是决心不太够,商业利益考虑更多些),那么国内应该重视研究如何将LLAMA系列更好中文化的相关技术(因为一些原因,LLAMA专门把中文能力弱化了,但是这其实不是大问题。做好的中文模型并不一定需要特别大量的中文数据,比如GPT 4),包括扩充中文Token词典、用中文训练数据低成本地进行继续预训练、有害信息的去除以通过审查等。这样随着Meta未来不断发布能力更强的新版本模型,国内有可能出现如此局面:通过LLAMA中文化得到的超强大模型(包括语言模型及多模态模型),出现的时间节点甚至快于绝大多数国内发布的最强大模型,包括闭源及开源大模型。
-如果几个月后市面上出现GPT 4级别(“中文化改造得较好+模型压缩比较成功”的LLAMA-3 400B模型)的开源文本及多模态模型,那么压力会给到国内大模型开发厂商,无论是开源还是闭源。 不排除国内之后会出现要求LLAMA的声音,原因其实很好找,还是希望不要走到这种局面。
-目前从模型能力而言,整体来说开源阵营确实是弱于闭源阵营的,这是事实,但是从最近一年半的技术发展来看,开源模型(包括国外和国内的模型)和最好闭源模型的差距是在逐步缩小的,而不是越来越拉大的,这也是事实,很多数据可以说明这一点。
- 那么什么因素会严重影响开源和闭源模型的能力差异呢?我觉得模型能力增长曲线的平滑或陡峭程度比较重要。如果模型能力增长曲线越陡峭(单位时间内,模型各方面能力的增长数量,越快就类似物体运动的“加速度”越大),则意味着短时间内需要投入越大的计算资源,这种情况下闭源模型相对开源模型是有优势的,主要是资源优势导致的模型效果优势。反过来,如果模型能力增长曲线越平缓,则意味着开源和闭源模型的差异会越小,追赶速度也越快。这种由模型能力增长曲线陡峭程度决定的开源闭源模型的能力差异,我们可以称之为模型能力的“加速度差”。
-让我们往后多看几年,之后开源和闭源模型的能力是逐步缩小还是逐步增大?这取决于我们在“合成数据”方面的技术进展。如果“合成数据”技术在未来两年能获得突破,则两者差距是有可能拉大的,如果不能突破,则开源和闭源模型能力会相当。所以,“合成数据”是未来两年大语言模型最关键的决定性的技术,很可能没有之一。
比较印象深刻的是,其中一位分享人介绍了自己做的人工智能识别肺部CT来判断某病的研究,其中强调了现在中国AI发展上的一些障碍。
模型上,在之前ChatGPT等都有公开过自己的代码,虽然在4以后不开源了,但是国内的程序员和算法工程师还是很多的,所以在模型上,只是稍有不同;
Meta是开源大模型的执旗者,在过去一段时间内,随着谷歌、xAI等陆续加入开源阵营,「开源or闭源」这一老生常谈的话题又再度回到舞台之中。不过对Meta来说,放出Llama 3 不是重点,对手的竞争、人才的流失,Meta还远没到「开香槟」的时刻。
在这场生成式AI浪潮中,之所以说在Meta迅速变革,原因有二:一个是区别于OpenAI等巨头的闭源路线,Meta加入战场的姿态是「开源」,这无疑为其争夺了更多的好感。
另一个原因则是扎克伯格本人对AI的态度,从过去混乱的AI策略转变为整合。关注无论是与微软合作,还是此次发布Meta AI加速与自家的产品生态融合,这都不难看出Meta在积极改变。
一位业内人士此前曾形容,今年的AGI竞赛不是「短跑」,更像是一场「马拉松」。对扎克伯格和他的Meta也是如此,据其采访透露,扎克伯格已经在考虑Llama 4、Llama 5,这会是一场更持久的竞争。
最近在工作之余,吴恩达连续分享了很多关于智能体的见解,并定义了AI Agent的四大设计模式,Reflection(反思)、Tool use(工具使用)、Planning(规划)和Multi-agent collaboration(多智能体协同):
-工具使用:LLM利用Web搜索、代码执行或任何其他功能的工具,来帮助自己收集信息、采取行动或处理数据。
-规划:LLM提出并执行实现目标的多步骤计划(比如一篇论文,首先写大纲,然后搜索和研究各部分内容,再写草稿)。
-多智能体协作:多个AI agent协同工作,分工任务,讨论和辩论想法,提出比单个智能体更好的解决方案。
2023年,北京信息软件业全行业营收规模已接近3万亿元,并持续多年保持2位数增长,成为推动全国信息软件业发展的重要引擎。当前,人工智能大模型和数据新型生产要素等“新动能”正在改变信息软件业的生产方式和发展模式,数字人等互联网“新业态”快速发展,具身智能、XR设备、AIPC(智能计算机)等新硬件不断对软件提出“新需求”,北京信息软件业正处于技术迭代升级、产业结构调整优化的关键变革期。
近期,开源和闭源之争再次引发行业内的激烈讨论。开源模型会越来越落后?Meta用Llama 3给出了回应。
Meta的这次表态,也显得意味深长:“我们致力于开放式人工智能生态系统的持续增长和发展,以负责任的方式发布我们的模型。我们一直坚信,开放会带来更好、更安全的产品、更快的创新和更健康的整体市场。这对Meta和社会都有好处。”

本文提到大模型通常的工作方式,即通过提示词进行问答,并指出了两个主要问题:历史对话信息的管理和令牌数量的限制。文章讨论了知识库问答和个人助手两个应用场景,并分析了各自面临的困境,如知识库无法有效处理多模态信息和大型文档,个人助手则受限于工具参数的复杂性和令牌长度。文章还提到了微调(FINE-TUNING)作为改善模型性能的方法,以及在不同领域的应用潜力。最后,分享了对微调成为标准操作流程的预期,以及对现有平台和基础设施的改进意见。
谷歌及其母公司 Alphabet 的首席执行官桑达尔・皮查伊 (Sundar Pichai)发文宣布了该公司的一些结构性变革,旨在 “提高整个公司的速度和执行力”。具体涵盖四个部分:模型和研究、负责任的人工智能、平台和设备以及使命第一。
皮查伊表示,他们正在将其研究部门和 DeepMind 部门专注于构建 AI 模型的团队整合为一个组织。通过此举,谷歌专注于 AI 安全的 Responsible AI 团队将从其研究组织转移到 DeepMind 部门,这样这些专家就可以与负责设计、构建和训练 Gemini 生成式 AI 模型的团队更有效地合作。
此次重组的核心是强化谷歌在AI领域的地位。反映了谷歌对于AI未来的重视,旨在通过整合硬件、软件和AI来推动计算技术的前进。这一举措可能会对谷歌的合作伙伴、竞争对手以及整个科技行业产生深远影响。由于Android系统在智能手机市场的主导地位,谷歌的任何重大变革都可能影响整个行业。
对于用户而言,短期内可能不会看到显著的变化,但长期来看,谷歌的这一策略可能会在AI驱动的产品和服务领域带来新的创新和体验。
其中明确,到 2027 年,北京市信息软件产业营业收入达到 4.8 万亿元。千亿级信息软件企业不少于 4 家,百亿级信息软件企业不少于 35 家。培育世界一流的信息软件企业,打造具有国际竞争力的信息软件产业集群。

这一系列举措表明北京市正积极推动信息软件产业的发展,特别是在AI和软硬件协同方面。这些措施不仅有助于提升北京市在全球信息软件产业的竞争力,也为其他城市和地区在信息软件产业的创新发展提供了宝贵的经验。同。

